AI Detectors Are Failing Honest Students
Turnitin's false positive rate in independent testing runs between 10% and 20%. The company's own marketing claims under 1%. In a school of 1,000 students, that gap means somewhere between 100 and 200 honest students could face academic misconduct charges this year for work they actually wrote. The problem isn't that detection software sometimes fails. The problem is that schools are treating a probabilistic statistical tool as a truth machine.
- Independent research consistently finds AI detectors produce false positive rates of 10% to 20% on authentic human writing, far higher than vendor claims.
- Detection tools measure statistical predictability, not authorship. Formal, rubric-following writing gets flagged for the same reason AI text does: both are predictable.
- ESL students, neurodivergent students, and high-achieving students who follow rubric instructions closely face the highest false positive risk.
- Turnitin's own documentation warns that scores should not be used as the sole basis for disciplinary action. Most schools ignore this.
- Process-based assessment, oral defences, and assignment redesign are more reliable than detection software for identifying genuine AI use.
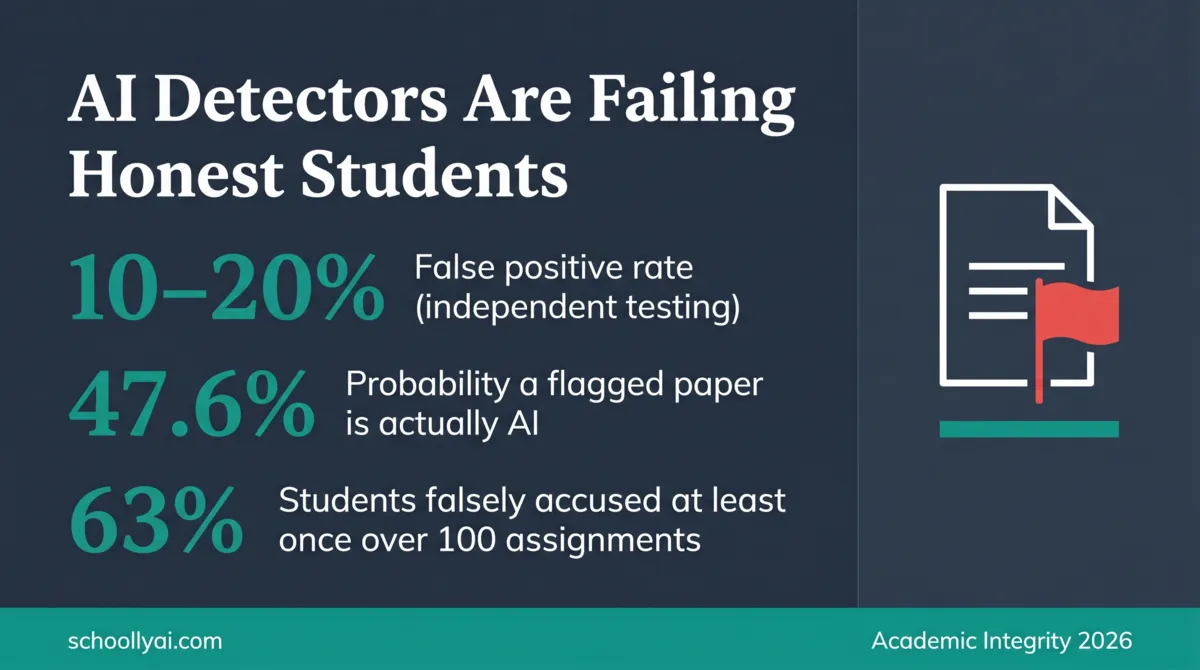
Independent testing shows AI detectors fail honest students at rates between 10% and 20%. Vendor claims of under 1% reflect controlled lab conditions, not real classrooms.
The Constitution Problem: When Good Writing Gets Flagged
Here is the thing that should stop every school administrator in their tracks. Feed the United States Constitution into a standard AI detection tool. Consistently, it comes back flagged as heavily or entirely AI-generated.
Not because the Constitution is plagiarised. Not because a student bought it online. But because the formalized language of constitutional documents is so deeply embedded in the training data of large language models that detection tools perceive its highly predictable phrasing as machine output. The algorithm is working exactly as designed. That's the problem.
If one of the most consequential documents in human history fails the test, a diligent 17-year-old who carefully follows their teacher's academic writing rubric is also going to fail the test. The same predictability that makes formal writing clear and structured is what detection algorithms flag as suspicious.
I have watched this play out in practice. Students who ordinarily produce average work, writing loosely and informally, sail through detection checks. Students who spend the weekend carefully revising their essays, following every instruction I gave them, come back flagged. The algorithm doesn't reward effort. It penalizes correctness.
What the Turnitin False Positive Rate Actually Shows
The largest independent evaluation of AI detection tools, analysed by Structural Learning in 2026, found consistent false positive rates of 10% to 20% on authentic human-written text. Turnitin markets its tool with claims of under 1% error. Both numbers cannot be right. The difference is where the testing happens.
Vendor accuracy claims come from controlled conditions with clean, clearly distinguishable training data. Real classrooms contain students who have varied writing styles, ESL learners who write with structured formality, neurodivergent students whose natural phrasing patterns differ from average, and high-achievers who write exactly as rubrics instruct. That population looks very different to the tool than a controlled lab sample.
The scale of the problem is not theoretical. At the University of Florida, AI-specific honor code violations surged from zero in 2023 to 66 reported cases in a single semester of 2025, according to public records reported by The Independent Florida Alligator in 2026. Not all of those cases involved genuine AI use. Some percentage were false positives that made it all the way to formal charges.
| Finding | Statistic | Source |
|---|---|---|
| False positive rate on human text | 10% to 20% | Weber-Wulff et al., 2023/2024 |
| OpenAI's own classifier: correct ID rate on AI text | 26% | UCLA Humanities Technology, 2024/2025 |
| OpenAI's classifier: false positive rate on human text | 9% | UCLA Humanities Technology, 2024/2025 |
| False positives at a 1% rate over 100 assignments | 63% probability of one false flag per student career | Reddit r/academia statistical analysis, 2024 |
| TOEFL essays flagged as AI by at least one major detector | 97% | Stanford University HAI, 2024 |
| Institutions using formal AI detection in disciplinary workflows | 60%+ | Thesify.ai Higher Ed Guide, 2026 |
That last statistic deserves its own sentence. Even if a detector had only a 1% false positive rate, far lower than what independent testing shows, a student who submits 100 assignments over their college career faces a 63% statistical probability of being falsely accused at least once. That is not a rare edge case. That is a structural feature of deploying probabilistic tools in high-stakes environments.
What AI Detectors Actually Measure (It's Not What You Think)
When a teacher sees a report saying a paper is "80% AI Generated," they reasonably assume the software found something definitive. A hidden watermark. A database match. Digital evidence of machine authorship. It found none of those things.
AI detectors measure two things: perplexity and burstiness. Perplexity measures how predictable the vocabulary is. A low perplexity score means the word choices are unsurprising, common, likely to appear in that sequence. Burstiness measures sentence length variation. Uniform sentence lengths produce low burstiness scores. High burstiness, with sentences swinging from short to long and back, is associated with human writing.
AI text tends to score low on both measures because it optimizes for the most statistically probable next word. Diligent students who use standard academic vocabulary and write carefully structured sentences also score low on both measures. The detector cannot distinguish between the two populations. It doesn't have access to intent. It only has the text.
The full technical breakdown is at What AI Detectors Actually Measure (And Don't), which covers perplexity, burstiness, and base rate math in plain language.
Who Gets Flagged Most Often
The false positive epidemic doesn't land evenly across a student population. Some students are structurally more exposed than others.
Students who follow rubric instructions closely write predictably by design. Rubrics that reward clear topic sentences, standard transitions, and formal vocabulary are, in effect, asking students to write the way an LLM writes. Then schools run those rubric-perfect essays through a tool that flags predictable text.
ESL students carry the heaviest penalty. A Stanford University HAI study from 2024 found that detectors flagged over 61% of TOEFL essays written by non-native English speakers as AI-generated. The algorithm reads that strategy as machine output. This is covered in detail in ESL Students and AI Detection Bias: The Algorithm Penalty.
Neurodivergent students face similar exposure. The Northern Illinois University Center for Innovative Teaching and Learning flagged in 2024 that neurodiverse students are disproportionately caught by AI detection tools due to algorithmic biases against non-standard linguistic patterns.
High-achievers who revise carefully and produce polished final drafts also run higher risk than students who submit rough, colloquial work. The irony is built into the system.
False Positive Risk Calculator
Answer four questions about the flagged essay. The tool will tell you how seriously to treat the detection score before taking any action.
1. Is the student an English Language Learner or identified as neurodivergent?
Vendors Know Their Tools Don't Work as Advertised
The most telling evidence about AI detector reliability doesn't come from independent researchers. It comes from the companies selling the tools.
OpenAI built an AI classifier to detect its own ChatGPT output. After testing, they permanently shut it down. The tool correctly identified only 26% of AI-written text while falsely flagging 9% of genuine human writing. OpenAI shut it down, according to reporting by UCLA Humanities Technology in 2024 and 2025.
Turnitin's 2026 release notes state explicitly that the tool "should not be used as the sole basis for adverse actions against a student" because it misidentifies both human and AI-generated text. The disclaimer is legally significant. Turnitin is acknowledging in writing that their product is not accurate enough to support disciplinary decisions.
The Math of Blame: Why Base Rates Make Everything Worse
Teachers reasonably assume that a high AI detection score means the paper was probably AI-generated. This is a base rate error. If a detector evaluates 1,000 papers and only 10% of students in that class are actually using AI, a paper flagged by the tool has only a 47.6% probability of actually being AI-generated.
Even a technically accurate tool becomes unreliable when cheating is not the norm. Schools treating a 95% AI detection score as near-certain proof of cheating are misreading what the number means.
What Teachers Should Do Instead
The research consensus in 2026 is clear: shift from detecting AI to making AI less useful as a cheat tool. Redesign assignments so that AI-generated text provides no advantage. That means requiring hyper-local context, specific classroom references, and documented research processes.
Students already facing a false accusation have a specific path forward. Falsely Accused of AI Cheating? Do This walks through process evidence and oral defences.
Teachers managing a live denial will find the technique in Student AI Denial vs. Evidence: A Teacher's Framework, which targets the cognitive struggle of writing.
The ESL Penalty Is Not a Side Issue
The AI detection bias against non-native English speakers is the single most documented and most ignored problem. If your school runs AI detection on ESL student work, you are running a linguistic discrimination engine.
The Stanford University HAI study found that detectors flagged over 61% of TOEFL essays as AI-generated. The algorithm penalizes learners who rely on standardized vocabulary and structured grammar. This is covered in ESL Students and AI Detection Bias: The Algorithm Penalty.
When a Student Denies It and You're Not Sure
The most reliable method available is a conversation that targets the cognitive struggle of writing. A student who actually wrote a paper can describe exactly where the friction was. A student who prompted an AI cannot.
Ask them to walk you through the structure of their argument. Ask what was hardest. Have them write a continuation in front of you. These questions reveal authentic engagement that no detection score can.
Expert Perspectives
James Zou, Professor at Stanford, summarised it in 2024: "The detectors are just too unreliable at this time, and the stakes are too high for the students." Detection alone does not preserve independent student work or prepare them for the future.
Frequently Asked Questions
Independent research consistently finds false positive rates of 10% to 20% on authentic human writing.
Sources
- Turnitin. AI Writing Detection Model. 2026. guides.turnitin.com
- Structural Learning. AI and Academic Integrity. 2026. structural-learning.com
Defending Academic Integrity in 2026
The AI Literacy mini-course covers how to build AI-resistant assessments. Free.
Start the Course →