Turnitin vs. GPTZero vs. Originality.ai: Which AI Detector Is Least Wrong?
Most schools are using Turnitin not because it performs best on AI detection, but because it came with the LMS contract. Independent testing from 2025 and 2026 shows that purpose-built educational detectors outperform legacy plagiarism checkers, particularly once students manually edit AI text. Understanding how each tool measures text is the prerequisite for choosing which one to trust with an academic integrity decision.
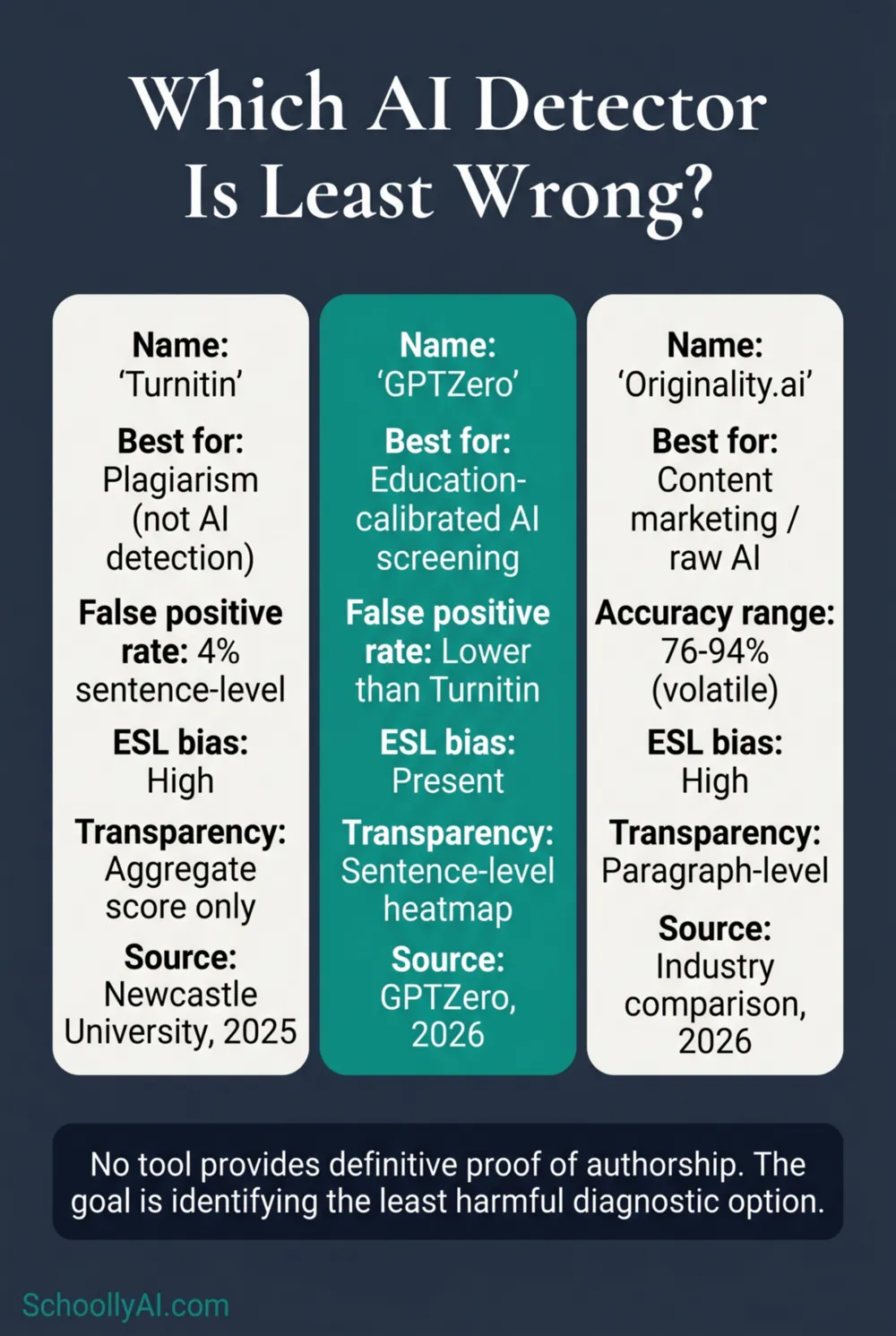
- Turnitin carries a 4% sentence-level false positive rate on structured academic writing and struggles with edited AI text, according to Newcastle University analysis from 2025.
- GPTZero is calibrated specifically for educational environments. Its sentence-level heatmaps show which specific sentences triggered the flag, not just an aggregate score.
- Originality.ai accuracy fluctuates between 76% and 94% depending on writing style. Its false positive rate on student essays is moderate to high.
- No tool provides definitive proof of authorship. The research question has shifted from finding the best detector to identifying the least harmful diagnostic option.
False positive rates and bypass vulnerability across the three major detection tools. Independent testing consistently produces lower accuracy figures than vendor claims.
Why the Tool You're Using Might Be the Wrong One
Most K-12 schools landed on Turnitin through institutional inertia. It was already integrated. The contract renewal included AI detection. Nobody ran an accuracy comparison before deploying it for academic integrity decisions. That is not a criticism of the administrators who made the call. It is the reality of how ed-tech adoption works in most districts.
The 2026 landscape has changed enough that staying with a default is now an active choice with real consequences. Teachers are flagging ESL students at rates that do not hold up to scrutiny. Detection scores are being challenged by parents who have read the same JISC and Newcastle University findings the vendor would prefer they hadn't. The question of which tool is most appropriate for which context is one worth answering before a dispute lands on a vice principal's desk.
How Independent Testing Differs From Vendor Claims
Vendor accuracy figures are generated under controlled lab conditions. Clean AI output is tested against clean human writing, matched for length and domain, with no revision or editing. Those conditions do not describe a real classroom.
Real classroom populations include ESL students writing formally in a second language, students who used AI for brainstorming and then wrote their own drafts, students who ran their work through Grammarly before submitting, and students who revised their AI-generated content manually. Every one of those populations produces text that looks different to a detector than clean human writing does.
The JISC AI Detection Assessment from June 2025 is the most rigorous UK benchmark available. It found that Copyleaks scored 100% accuracy on one dataset and 0% on a slightly modified version of the same dataset. That result does not reflect a poorly built tool. It reflects how fragile the underlying statistical models are when real-world variation is introduced.
Turnitin: The Contract Default
Turnitin's core strength is its plagiarism database. Decades of student submissions give it an unmatched resource for detecting copied text. That strength does not extend to AI detection.
The AI detection module returns a single aggregate probability score with no sentence-level transparency. A teacher sees 74% and has no way to know which sentences triggered it, what perplexity threshold was applied, or how the student's established writing baseline factors in. It does not.
Newcastle University's August 2025 analysis found a 4% sentence-level false positive rate on structured academic writing, which is the exact population teachers are trying to assess. Turnitin's response was an August 2025 update adding a new category to flag AI-paraphrased text. That update confirms the bypass problem rather than solving it. The category exists because humanizer tools were already defeating the original detection reliably.
Turnitin's own documentation states the tool should not be used as the sole basis for punitive action. That disclaimer matters for liability. It does not filter through to the teachers receiving the alert in their LMS dashboard.
GPTZero: The Education-Calibrated Option
GPTZero was built specifically for academic use, which makes it structurally different from tools adapted from content marketing or plagiarism detection. The sentence-level heatmap is the feature that matters most in a classroom context. A teacher can see exactly which sentences triggered the flag rather than reading backwards from an aggregate score.
That granularity changes the conversation. A teacher who can point to three specific sentences and ask the student to explain them has a starting point for a real discussion. A teacher who can only say "the system says 74%" has nothing defensible.
GPTZero also provides greater methodological transparency than Turnitin. Its documentation explains what it measures and what it does not. That transparency matters when a teacher needs to explain a detection result to a parent or appeal a contested finding to administration.
The 99% claimed accuracy figure GPTZero publishes is a vendor figure from controlled testing. Independent benchmarks show lower performance on edited AI text, as they do with every tool. The relevant comparison is not GPTZero's claimed accuracy against Turnitin's. It is GPTZero's false positive rate on real student writing versus Turnitin's.
Originality.ai: The Commercial Contender
Originality.ai was designed for content marketing use cases and adapted for academic integrity. That origin matters. Its training prioritises detecting raw AI content from platforms like ChatGPT and Claude. It performs better on unedited AI output than on student writing that mixes AI drafting with human revision.
The accuracy band of 76-94% reflects exactly that volatility. On clean AI output it approaches the top of that range. On a student essay that used AI for brainstorming and then rewrote the draft in their own voice, it approaches the bottom. That variability is problematic for high-stakes academic integrity decisions where the teacher needs consistent behaviour from the tool, not probabilistic swings based on writing style.
Originality.ai is arguably the best tool available for content teams checking whether a contractor submitted AI-generated copy. It is not the best fit for a classroom where the student population is heterogeneous and formal academic writing style produces false positives.
Head-to-Head: What the Independent Research Shows
| Criterion | Turnitin | GPTZero | Originality.ai |
|---|---|---|---|
| False positive rate on structured academic writing | 4% sentence-level (Newcastle, 2025) | Lower than Turnitin; vendor cites historically low rates | Moderate to high; volatile across writing styles |
| ESL bias | High. Low-perplexity formal writing triggers consistently | Present. Calibrated for education but not ESL-specific | High. Content-marketing origin amplifies formal writing bias |
| Bypass vulnerability | High. Humanizer tools reduce accuracy to 60-80% | High. No tool is immune to burstiness injection | High. Most vulnerable on manually edited AI text |
| Sentence-level transparency | No. Aggregate score only | Yes. Sentence-level heatmap | Partial. Paragraph-level highlighting |
| LMS integration | Canvas, Schoology, Google Classroom | Limited direct LMS integration | API access; limited native LMS integration |
| Best use case | Plagiarism detection (not AI detection) | Classroom AI integrity conversations | Content marketing / unedited AI output |
The bypass vulnerability row applies equally across all three tools. Any student motivated enough to run their submission through a humanizer tool defeats all three detectors. The relevant question is not which tool catches determined cheaters. It is which tool produces the fewest false accusations against honest students.
Which Tool Fits Which Classroom Context
ESL-heavy classroom: no detection tool is appropriate as primary evidence. The Stanford HAI finding that 97% of TOEFL essays are falsely flagged as AI makes any tool a liability in that context. Process verification is the only defensible approach.
General high school with mixed writing ability: GPTZero used as a conversation-opener, not a verdict-giver. Its sentence-level heatmap gives teachers something specific to discuss rather than a number to defend. Cross-reference with a second tool before raising anything formally.
College-prep or university-bound cohort: process verification should replace tool reliance entirely. These students are producing the most sophisticated writing and are most likely to be falsely flagged. Version history and a brief verbal check produce better evidence than any detector.
Students who want to bypass detection tools will succeed regardless of which tool you choose. The detector comparison matters for reducing false accusations against honest students, not for catching dishonest ones.
Which detector fits your classroom?
FAQ
Independent research points to GPTZero as the most education-calibrated option. It offers sentence-level granularity, lower false positive rates than Turnitin on structured academic writing, and greater methodological transparency. No tool provides definitive proof of authorship. GPTZero is the least harmful diagnostic option currently available for classroom use.
Not reliably. Newcastle University analysis in 2025 found a 4% sentence-level false positive rate on structured academic writing. Turnitin's primary strength is its plagiarism database depth, not AI detection accuracy. Its August 2025 update adding a category for AI-paraphrased text was a reactive response to bypass tools that already made the original detection largely ineffective.
Yes, heavy Grammarly use can lower the burstiness of a text and produce a false positive. Grammarly regularises sentence length and vocabulary choices in ways that detection tools associate with AI output. Students who use authorised editing tools should include a disclosure statement noting that Grammarly was used.
Each tool uses a different training dataset and a different threshold for what counts as AI text. Copyleaks scored 100% accuracy on one dataset and 0% on a slightly modified version of the same dataset, according to the JISC AI Detection Assessment in 2025. The tools are not measuring the same statistical signature in the same way, which is why the same paper can score 82% on one tool and 11% on another.
Sources
- Grundy, D. The Unfairness of AI-Flagged Academic Misconduct Investigations in UK Universities. Newcastle University. August 2025. blogs.ncl.ac.uk
- JISC. AI Detection and Assessment: An Update for 2025. National Centre for AI. June 2025. nationalcentreforai.jiscinvolve.org
- GPTZero. Best AI Content Detectors Compared. 2026. gptzero.me
- Turnitin. AI writing detection model updates. Release Notes. August 2025. guides.turnitin.com
- Thesify.ai. How Professors Detect AI Writing: 2026 Guide. 2026. thesify.ai
- Reddit / r/BestAIDetectors. Best AI Detector Tools of 2026. 2026. reddit.com/r/BestAIDetectors
- Zou, James, et al. GPT Detectors Are Biased Against Non-Native English Writers. Stanford HAI. 2024. hai.stanford.edu
The tool comparison only matters in the context of what the scores mean. The AI Literacy mini-course covers how to read detection results, when to act on them, and what to do instead. Free. No email required.
Start the AI Literacy Course →